简介
ParNew和CMS最大的痛点就是STW(Stop The World),所以之后出现的G1垃圾回收器的优化是朝着减少STW的目标去做的。
G1特点之一是把java堆内存拆分成为多个大小相等的Region,新生代和老年代的概念只不过是逻辑上的。G1垃圾回收器是可以同时回收新生代和老年代的对象的,不需要两个垃圾回收器配合起来运作。
G1垃圾回收器另一个特点是设置了一个垃圾回收停顿时间,回收的时候尽可能挑选停顿时间短以及回收对象最多的Region,保证GC对系统停顿的影响在可控范围内。(Par+CMS的主要要花都在减少Minor GC和Full GC)
设定G1的内存大小
当有参数“-XX:UseG1GC”来指定使用G1回收器时,会自动用堆大小除以2048得出每个region的大小。刚开始默认新生代堆内存的占比是5%,对应大概100个region,通过“-XX:G1NewSizePercent”初始化。
-Xms
-Xmx
-XX:UseG1GC
-XX:G1HeapRegionSize //HeapSize/2048或者指定
-XX:G1NewSizePercent //5%
-XX:G1MaxNewSizePercent //60%
新生代中的Eden和Survivor
G1新生代中依然有Eden和Survivor的划分,初始化时有80可能是Eden,两个Survivor都是10个,随着新生代Region的增加,Eden和Survivor对应的Region也会不断的增加。
-XX:SurvivorRatio:8
-XX:MaxGCPauseMills //200ms
G1新生代的垃圾回收
一旦新生代达到了“-XX:G1MaxNewSizePercent”设定的60%,会触发“新生代的GC”。G1对每个Region都会追踪回收时间,选择回收一部分Region。保证MaxGCPauseMills时间内被回收最多。
什么时候进入老年代
在新生代的对象达到以下条件就会进入老年代。
- 达到一定年龄 -XX:MaxTenuringThreshold
- 动态年龄判断规则,如果一旦发现某次新生代GC后,n岁以下的存活对象超过Survivor的 50%,那么n岁以上的对象全部进入老年代。
大对象Region
G1提供了专门的Region来存放大对象,超过一个region大小的50%的对象就算是大对象。如果一个对象太大会横跨多个region来存放。之前应许60%给新生代,40%给老年代但是这些都是动态的,回收后就不在具有任何标签可以分配给大对象。大对象没有像新生代60%和老年代40%的回收水位线,所以大对象会在新生代和老年代回收的时候顺带回收一波。
G1和ParNew在新生代的对比优势
说一千道一万最大的优势还是在于STW时间的可控上。调优思路还是减少耗时的垃圾回收,也就是避免对象进入老年代。传统的垃圾收集器是通过调整s区和e区的大小来控制,而G1则比较先进,直接指定一个期望的停顿时间,选择停顿时间的标准是既不能频繁触发minor gc,也不能一次回收过多的对象,所以还得通过工具来调试出一个最适合自己系统的停顿时间。通过工具检测,要得出一个停顿多久可以回收多少的内存大小的指标。根据这个指标和业务系统生成垃圾的速率设置合理的停顿时间。
新生代+老年代混合GC
-XX:InitiatingHeapOccupancyPercent //45%
意思是老年代占据堆内存45%的Region的时候,尝试混合回收。大概是接近1000个region。
G1垃圾回收的过程
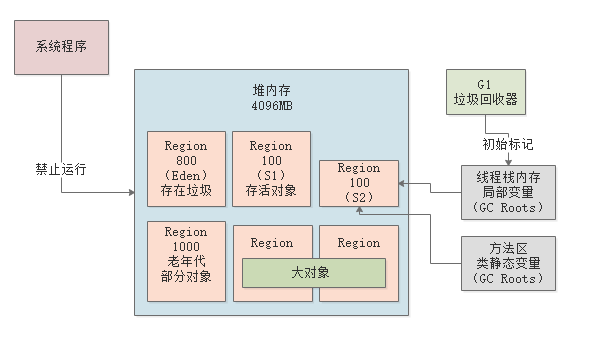
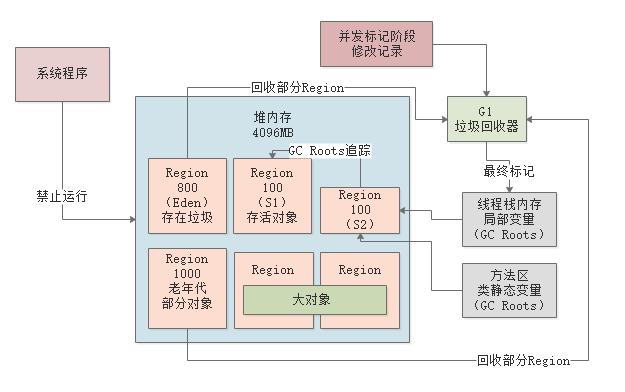
首先出发“初始标记”的操作,进入STW,仅标记GC Roots直接能引用的对象。这个过程很快。
初始标记
如下图,先停止系统程序的运行,然后对各个线程内存中的局部变量代表的GC Roots,以及方法区中的类静态变量代表的GC Roots,进行扫描,标记出来他们直接引用的对象。
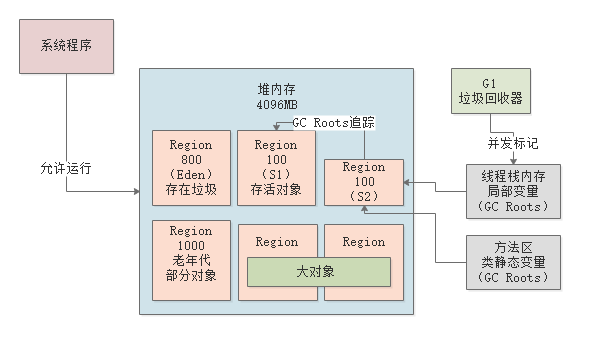
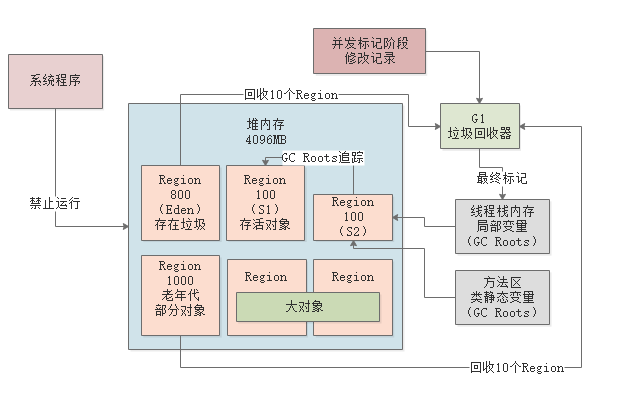
并发标记
接着会进入“并发标记”的阶段,这个阶段允许系统程序的运行,同事进行GC Roots追踪,从GC Roots开始追踪所有的存活对象,如下图所示。
这里对GC Roots追踪做更详细的说明,比如下面的代码:
public class Kafka{
public static ReplicaManager replicaManager = new ReplicaManager();
}
public class ReplicaManager{
public ReplicaFetcher replicaFetcher = new ReplicaFetcher();
}
Kafka这个类有一个静态变量“replicaManager”,是一个GC Roots对象,初始标记阶段仅仅标记“replicaManager”的直接关联对象“ReplicaManager”。
然后并发标记阶段会进行GC Roots追踪,会从“replicaManager”的直接关联对象“ReplicaManager”开始往下追踪。可以看“ReplicaManager”有一个实例变量“replicaFetcher”,此时追踪“replicaFetcher”可以看到引用的“ReplicaFetcher”对象,那么此时这个“ReplicaFetcher”也要被标记为存活对象。
JVM会对并发标记阶段对对象作出一些修改记录,比如哪个对象被新建了,哪个失去了引用。
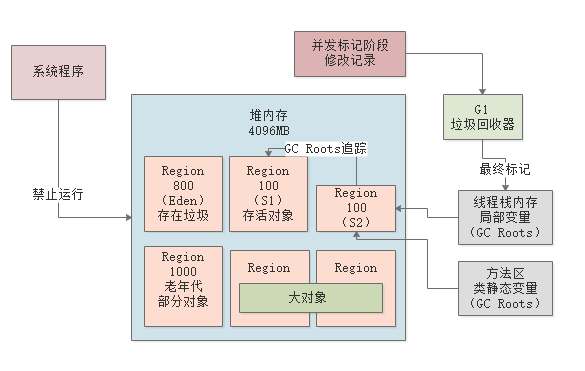
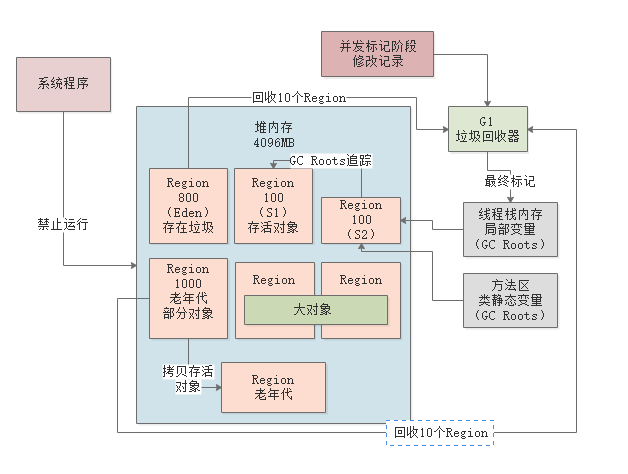
最终标记
下个阶段最终标记阶段,这个阶段会进入STW,系统禁止运行,但是会根据并发标记阶段记录的对象修改,最终标记一下有哪些存活对象。
最后一个阶段就是混合回收的阶段,这个阶段会计算老年代中每个region的存活对象数量,存活对象的占比,还有执行垃圾回收的预期性能和效率。
接着会停止系统,然后尽快进行垃圾回收,此时会选择部分Region进行回收,因为必须让垃圾回收的停顿时间控制在我们指定的时间内。
混合回收
比如老年代现在有1000个region都满了,但是因为根据预定目标,本次垃圾回收可能只能停顿200ms,通过之前的计算,800个region刚好要200ms,那么就只会回收800个Region。
这里涉及的参数+XX:MaxGCPauseMills
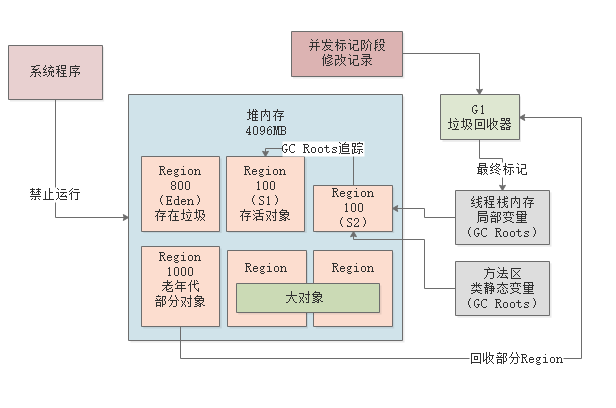
在老年堆占比达到45%的时候,触发的是“混合回收”,不仅仅会回收老年代,还有新生代和大对象。从这些区中各自挑选一些region,保证在MaxGCPauseMills中尽可能多的回收。
混合回收(MixedGC)可以执行多次,“-XX:G1MixedGCCountTarget”参数就是在一次混合回收的过程汇总,最后一个阶段执行几次混合回收,默认是8次。
假设一次混合回收预期要回收掉160个region,那么第一次混合回收会收掉一部分比如20个。
如此反复执行8次就能把160个region全部回收,并且把系统停顿时间控制在指定范围内。这样可以在回收的间隙让系统正常运行一会。
还有一个参数就是“-XX:G1HeapWastePercent”,默认值是5%,他的意思是说在混合回收的时候,对Region的回收都是基于复制算法进行的,都是把要回收的Region里的存活对象放入其他的Region,然后找个Region中的垃圾对象全部清理掉。
这样的话在回收过程中就会不断空出来新的Region,一旦空闲出来的Region数量达到了堆内存的5%,此时就会立刻停止混合回收,意味这本次混合回收就结束了。
还有一个限制回收的条件即“-XX:G1MixedGCLiveThresholdPercent”,默认值是85%,意思是被回收region中的存活对象必须小于85%,大于85%复制算法的回收成本会很高。
回收失败
在进行Mixed回收的时候,拷贝过程中如果没有空闲的region承载自己的存活对象,会触发一次失败。一旦失败就会停止系统程序,采用单线程标记、清理和压缩整理。
实际案例分析
背景引入
一个百万级注册用户的在线教育平台,高频行为时晚上两三个小时上课。
核心业务流程
现在强调欢快娱乐中进行教学,核心业务的流程就是大量的游戏互动环节。通过游戏互动让孩子感兴趣,愿意学,而且通过游戏强互动让他们保持注意力,促使他们对学习到的东西进行输出,提升学习的效果。系统得记录下来用户完成了多少个任务,做对了几个,做错了几个,诸如此类的。
系统的运行压力
分析一波,晚上高峰期内,每秒会有多少请求。大致的估算一下,晚上3小时高峰期内总共60万活跃用户,平均每个用户大概会使用1小时左右来上课,那么每个小时大概会有20万活跃用户同时在线学习。平均每分钟进行1次互动操作,一小时内忽悠1200万次操作,凭据每秒大概是3000次左右的互动操作。一般的核心服务需要部署5台4核8G的机器来抗住是差不多的,每台机器每秒钟抗600请求。一次互动大致连带创建几个对象,占几KB的内存,如果是5KB那么一秒600请求会占用3MB左右的内存。G1本身运行机制较为复杂,集合案例把部分优化说清楚。
G1默认的内存布局
回顾上一节中的内存压力分析,4核8G的机器来部署,每台机器每秒会有600个请求会占用3MB左右的内存空间。假设分配4G给堆内存,其中新生代初始默认比为5%。最大占比60%。每个java线程的栈内存为1MB,元数据区域(永久代)的内存为256M,至关重要的系统停顿时间(STW)默认200ms,此时JVM参数如下
-Xms4096M
-Xmx4096M
-Xss1M
-XX:PermSize=256M
-XX:MaxPermSize=256M
-XX:+UseG1GC
-XX:G1NewSizePercent=5
-XX:G1MaxNewSizePercent=60
-XX:MaxGCPauseMills=200
假设有一个前提,G1回收300个Region(600MB内存),大致需要200ms。那么很有可能系统运行时,G1呈现出如下的运行效果。
首先每秒创建3MB的对象,大概1分钟左右就会塞满100个region(200MB),此时G1可能会觉得要是触发一次GC一分钟后还要接着出发,不如继续增加新生代,一直到300个Region都占满了,此时出发GC大概需要200ms。但是这些都只是假设,G1的时间约束导致结果,实际是怎样的是无法完全准确预知的。
需要结合系统压测工具,gc日志,内存分析工具结合起来进行考虑,尽量让系统的gc停顿时间也别太长,达到一个理想的合理值。而所有的一切调优都集中在MaxGCPauseMills这个参数上。
G1压缩内存空间会比较有优势,适合会产生大量碎片的应用;G1能够可预期的GC停顿时间,对高并发应用更有优势。其他垃圾收集器对大内存回收耗时较长,G1对内存分成多块区域,能够根据预期停顿时间选择性的对垃圾多的区域进行回收,适用多核、jvm内存占用大的应用。parNew+cms回收器比较适用内存小,对象能够在新生代中存活周期短的应用